Bài viết gần đây
-
Tự động hóa cơ bản bằng Python: Giải phóng sức lao động văn phòng
Tháng 5 28, 2026
| Lập trình Python xử lý PDF tự động: Giải phóng sức lao động văn phòng thực chiến
Được viết bởi thanhdt vào ngày 28/05/2026 lúc 17:11 | 21 lượt xem

Trong guồng quay công việc văn phòng hiện đại, PDF là một trong những định dạng tài liệu phổ biến nhất. Từ hợp đồng, hóa đơn, báo cáo tài chính cho đến CV ứng viên – tất cả đều được đóng gói dưới dạng PDF để đảm bảo tính bảo mật và định dạng đồng nhất.
Tuy nhiên, sự bảo mật và đồng nhất đó lại là "cơn ác mộng" đối với những ai muốn khai thác dữ liệu từ chúng.
- Bạn phải mở thủ công hàng chục file hợp đồng PDF, tìm kiếm số tiền rồi gõ lại vào file Excel.
- Bạn là HR và phải đọc hàng trăm file CV PDF chỉ để lọc ra các ứng viên biết kỹ năng "Python" hoặc "Data Analyst".
- Bạn tốn hàng giờ đồng hồ mỗi tuần cho việc copy-paste nhàm chán và rất dễ xảy ra sai sót.
Đã đến lúc chấm dứt sự lãng phí thời gian này. Với Python và thư viện pdfplumber, bạn có thể tự động hóa 100% quy trình đọc, tìm kiếm và trích xuất dữ liệu từ bất kỳ file PDF nào chỉ trong vài dòng code.
Hôm nay, Hướng Nghiệp Dữ Liệu sẽ hướng dẫn bạn làm chủ kỹ thuật xử lý PDF đỉnh cao này!
🎨 Trận đồ Quy trình xử lý PDF tự động bằng Python
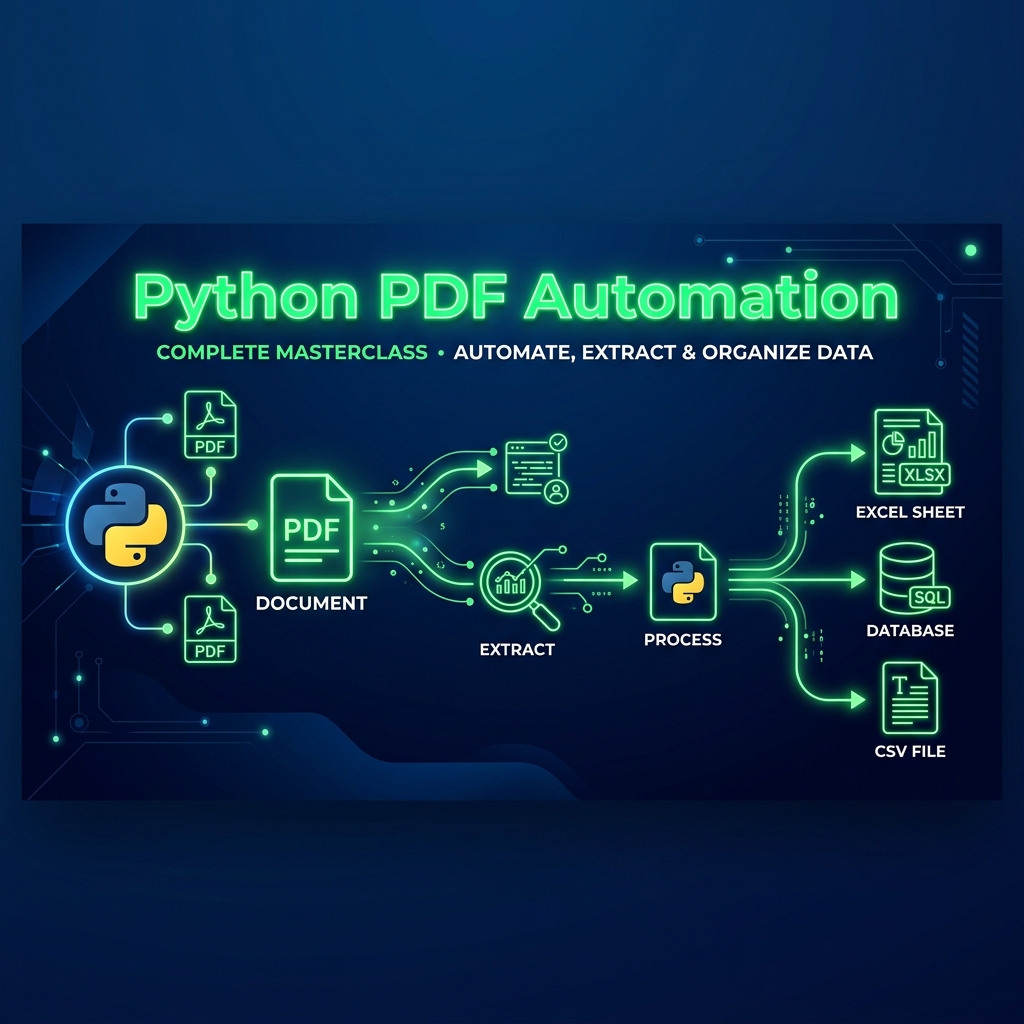
1. Tại sao lại chọn pdfplumber thay vì các thư viện khác?
Trong hệ sinh thái Python, có nhiều thư viện hỗ trợ làm việc với PDF như PyPDF2, pdfminer, hay fitz (PyMuPDF). Tuy nhiên, pdfplumber nổi lên là sự lựa chọn số một cho việc tự động hóa văn phòng vì các ưu điểm vượt trội:
- Trích xuất văn bản cực kỳ chính xác: Giữ nguyên vị trí cấu trúc từ, khoảng cách dòng giúp dữ liệu không bị dính chữ hay mất ký tự tiếng Việt.
- Hỗ trợ trích xuất bảng biểu (Table Extraction) đỉnh cao: Khả năng tự động nhận diện lưới bảng và chuyển đổi thành DataFrame của
pandaschỉ bằng 1 câu lệnh. - Giao diện lập trình (API) thân thiện, dễ sử dụng: Rất phù hợp với người mới bắt đầu hoặc dân văn phòng không chuyên về IT.
Để cài đặt pdfplumber, bạn chỉ cần chạy lệnh sau trên Terminal:
pip install pdfplumber
2. Đọc tệp PDF cơ bản với pdfplumber
Hãy bắt đầu với tác vụ cơ bản nhất: Mở một tệp PDF, đọc toàn bộ nội dung và in ra màn hình.
Chương trình đọc tệp PDF mẫu:
import pdfplumber
# Đường dẫn tới file PDF của bạn
pdf_path = "hop_dong_mau.pdf"
# Mở file PDF sử dụng ngữ cảnh 'with' để tự động đóng file sau khi xử lý xong
with pdfplumber.open(pdf_path) as pdf:
# Lấy trang đầu tiên (index bắt đầu từ 0)
first_page = pdf.pages[0]
# Trích xuất toàn bộ văn bản của trang này
text = first_page.extract_text()
print("--- NỘI DUNG TRANG ĐẦU TIÊN ---")
print(text)
📝 Bài tập thực hành 1:
Đề bài: Hãy viết một script Python mở một file PDF bất kỳ có nhiều trang, tự động đếm xem file đó có bao nhiêu trang, trích xuất nội dung của tất cả các trang và in ra màn hình.
Mã nguồn lời giải tham khảo:
import pdfplumber
def read_all_pdf(file_path):
with pdfplumber.open(file_path) as pdf:
total_pages = len(pdf.pages)
print(f"Tổng số trang của tài liệu: {total_pages}n")
for index, page in enumerate(pdf.pages):
print(f"--- TRANG {index + 1} ---")
page_text = page.extract_text()
if page_text:
print(page_text)
else:
print("[Thông báo] Trang này trống hoặc là ảnh quét.")
print("-" * 30)
# Chạy thử nghiệm
# read_all_pdf("tai_lieu_cua_ban.pdf")
3. Ví dụ thực tế: Trích xuất thông tin hợp đồng và hóa đơn tự động
Hãy tưởng tượng bạn có hàng trăm tệp PDF hóa đơn có cấu trúc cố định và bạn cần trích xuất: Mã hóa đơn (Invoice ID), Ngày xuất (Date), và Tổng tiền thanh toán (Total Amount) để đưa vào báo cáo tài chính Excel.
Chúng ta sẽ kết hợp Regular Expressions (Regex – Biểu thức chính quy) để tìm kiếm dữ liệu một cách thông minh dựa trên quy luật định dạng chữ.
graph TD
A[Mở file hóa đơn PDF] --> B[Trích xuất toàn bộ Text văn bản]
B --> C{Sử dụng Regex quét mẫu dạng khớp}
C -->|Mã hóa đơn| D[Tìm mẫu: HD-XXXX]
C -->|Ngày ký| E[Tìm mẫu: DD/MM/YYYY]
C -->|Tổng tiền| F[Tìm mẫu: X.XXX.XXX VNĐ]
D & E & F --> G[Đóng gói thành cấu trúc dữ liệu]
G --> H[Xuất báo cáo tự động sang file Excel]
Mã nguồn trích xuất dữ liệu thực tế:
import pdfplumber
import re
import pandas as pd
def extract_invoice_data(pdf_file_path):
with pdfplumber.open(pdf_file_path) as pdf:
# Giả định thông tin quan trọng nằm ở trang 1
page_content = pdf.pages[0].extract_text()
# Thiết lập các mẫu tìm kiếm bằng Regex
# 1. Tìm mã hóa đơn dạng: HD-2026-0001
invoice_pattern = r"HD-d{4}-d{4}"
invoice_id = re.search(invoice_pattern, page_content)
# 2. Tìm ngày ký dạng: 28/05/2026
date_pattern = r"d{2}/d{2}/d{4}"
signing_date = re.search(date_pattern, page_content)
# 3. Tìm tổng số tiền thanh toán dạng: 15.500.000 VNĐ
amount_pattern = r"([d.]+)s*VNĐ"
amount = re.search(amount_pattern, page_content)
# Trích xuất giá trị kết quả
res_invoice = invoice_id.group(0) if invoice_id else "Không tìm thấy"
res_date = signing_date.group(0) if signing_date else "Không tìm thấy"
res_amount = amount.group(1) if amount else "Không tìm thấy"
return {
"Mã hóa đơn": res_invoice,
"Ngày xuất": res_date,
"Tổng tiền (VNĐ)": res_amount
}
# Chạy thử nghiệm và lưu kết quả báo cáo
# data = extract_invoice_data("hoa_don_1.pdf")
# df = pd.DataFrame([data])
# df.to_excel("bao_cao_tai_chinh.xlsx", index=False)
# print("Đã tổng hợp báo cáo tài chính thành công!")
4. Tìm kiếm nội dung cụ thể: Sàng lọc CV ứng viên thông minh
Với vai trò tuyển dụng (HR), việc lọc hàng trăm CV thủ công để tìm kiếm từ khóa kỹ năng (như Python, SQL, FastAPI, Machine Learning) vô cùng mất thời gian. Bạn hoàn toàn có thể viết một chương trình Python tự động quét qua thư mục chứa hàng loạt file CV PDF để lọc ra những CV đạt yêu cầu.
📝 Bài tập thực hành 2:
Đề bài: Hãy viết một chương trình Python thực hiện các nhiệm vụ sau:
- Đọc một file CV ứng viên dạng PDF.
- Tìm kiếm danh sách các từ khóa kỹ năng yêu cầu trong nội dung CV.
- Xuất kết quả báo cáo đánh giá ứng viên ra một tệp văn bản
.txtđể gửi cho bộ phận kỹ thuật xem xét.
Lời giải chi tiết:
import pdfplumber
import os
def screen_cv(cv_pdf_path, keywords, output_txt_path):
print(f"Đang phân tích CV: {os.path.basename(cv_pdf_path)}...")
# 1. Trích xuất toàn bộ văn bản trong CV
full_text = ""
with pdfplumber.open(cv_pdf_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
if text:
full_text += text + "n"
# Chuyển văn bản thành chữ thường để so sánh không phân biệt hoa thường
full_text_lower = full_text.lower()
# 2. Tìm kiếm các từ khóa kỹ năng
matched_skills = []
missing_skills = []
for skill in keywords:
if skill.lower() in full_text_lower:
matched_skills.append(skill)
else:
missing_skills.append(skill)
# Tính điểm phần trăm kỹ năng đáp ứng
match_percentage = (len(matched_skills) / len(keywords)) * 100
# 3. Xuất kết quả ra file văn bản .txt
with open(output_txt_path, 'w', encoding='utf-8') as out_file:
out_file.write(f"=== BÁO CÁO PHÂN TÍCH ỨNG VIÊN ===n")
out_file.write(f"Tên tệp CV: {os.path.basename(cv_pdf_path)}n")
out_file.write(f"Mức độ tương thích: {match_percentage:.1f}%n")
out_file.write(f"----------------------------------n")
out_file.write(f"Kỹ năng ĐẠT YÊU CẦU ({len(matched_skills)}):n")
for s in matched_skills:
out_file.write(f" [x] {s}n")
out_file.write(f"nKỹ năng THIẾU ({len(missing_skills)}):n")
for s in missing_skills:
out_file.write(f" [ ] {s}n")
print(f"🎉 Đã phân tích xong! Báo cáo được xuất ra tại: {output_txt_path}")
# Chạy thử nghiệm thực tế
if __name__ == "__main__":
skills_to_find = ["Python", "SQL", "Data Analysis", "FastAPI", "Power BI", "Docker"]
# screen_cv("CV_Nguyen_Van_A.pdf", skills_to_find, "bao_cao_ung_vien.txt")
🎓 Khóa học "Tự động hóa cơ bản bằng Python" tại Hướng Nghiệp Dữ Liệu
Việc xử lý tài liệu PDF tự động chỉ là một trong những mảnh ghép nhỏ trong bức tranh tổng thể về Tự động hóa công việc văn phòng (Work Automation).
Để đồng hành cùng bạn trên con đường giải phóng sức lao động văn phòng, tối ưu hóa năng suất làm việc gấp 5 lần, Hướng Nghiệp Dữ Liệu mang đến Khóa học "Tự động hóa cơ bản bằng Python":
- Thời lượng: 16 buổi học trực chiến, cầm tay chỉ việc.
- Dành cho: Dân văn phòng, kế toán, HR, kinh doanh… hoàn toàn chưa từng biết lập trình.
- Kiến thức học được:
- Tự động hóa các tệp tin tài liệu văn phòng: Word, Excel, CSV, PDF.
- Lập trình robot cào dữ liệu từ các website về máy tự động.
- Kết nối hệ sinh thái API: Đăng bài tự động lên Fanpage Facebook, gửi Email hàng loạt chăm sóc khách hàng qua Amazon SES/Gmail.
- Thiết kế giao diện Web Dashboard quản lý và theo dõi tiến trình tự động hóa tập trung.
🔥 Kết luận: Hãy làm việc thông minh hơn, chứ không phải chăm chỉ hơn
Học kỹ năng tự động hóa bằng Python không đơn thuần là học lập trình, mà là bạn đang đầu tư tự mua lại thời gian của chính mình. Hãy giao phó những công việc giấy tờ, tệp tin lặp đi lặp lại nhàm chán cho máy tính xử lý và dành quỹ thời gian quý báu đó cho những công việc sáng tạo, mang lại giá trị cao hơn.
👉 Hãy bắt đầu tự động hóa công việc của bạn ngay từ hôm nay!
Đăng ký nhận tư vấn lộ trình học tập chi tiết và nhận bộ tài liệu tự động hóa thực chiến miễn phí của Hướng Nghiệp Dữ Liệu qua Zalo:
💬 LIÊN HỆ TƯ VẤN TRỰC TIẾP QUA ZALO
Thông tin chi tiết về lịch khai giảng khóa học xem thêm tại: Tự động hóa cơ bản
🌐 Đọc chi tiết bài viết và đăng ký khóa học tại Website: https://huongnghiepdulieu.com/?p=5355