Bài viết gần đây
| Phân Tích Thống Kê Mô Tả Với Python (Descriptive Statistics)
Được viết bởi thanhdt vào ngày 09/12/2025 lúc 19:02 | 213 lượt xem
")
Phân Tích Thống Kê Mô Tả Với Python (Descriptive Statistics)
Phân tích thống kê mô tả giúp bạn hiểu:
- Dữ liệu phân bố như thế nào?
- Giá trị trung bình – trung vị – độ lệch chuẩn
- Biến động dữ liệu ra sao?
- Dữ liệu có bị lệch, có nhiều outliers không?
- Nhóm nào, sản phẩm nào, tháng nào có hiệu suất cao nhất?
Đây là nền tảng để tiếp tục phân tích sâu hơn và xây dựng mô hình dự báo.
1. Tạo dữ liệu mẫu
import pandas as pd
df = pd.DataFrame({
"revenue": [120, 150, 180, 200, 130, 170, 160],
"cost": [30, 50, 40, 60, 35, 45, 55],
"category": ["A","A","B","B","A","C","C"]
})
2. Xem thống kê nhanh với describe()
df.describe()
Kết quả gồm:
- count
- mean
- std (độ lệch chuẩn)
- min
- 25%
- 50%
- 75%
- max
Đây là bước “nhìn tổng quan” cực nhanh.
3. Các thống kê cơ bản (Mean, Median, Mode)
Trung bình
df["revenue"].mean()
Trung vị
df["revenue"].median()
Mode (giá trị xuất hiện nhiều nhất)
df["category"].mode()
4. Độ lệch chuẩn & Phương sai (Std, Variance)

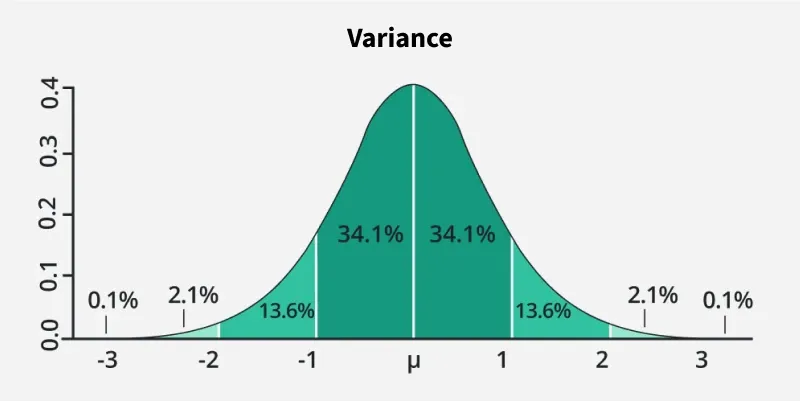

Phương sai:
df["revenue"].var()
Độ lệch chuẩn:
df["revenue"].std()
Std cao → biến động lớn → rủi ro cao
5. Hệ số biến thiên (Coefficient of Variation)
Đo mức độ biến động tương đối.
cv = df["revenue"].std() / df["revenue"].mean()
6. Phân tích theo nhóm (Groupby)
Nhóm theo category:
df.groupby("category")["revenue"].mean()
Đếm số lượng:
df.groupby("category").size()
Nhiều chỉ số cùng lúc:
df.groupby("category").agg({
"revenue": ["mean","sum","count"],
"cost": ["mean","max"]
})
7. Phân phối dữ liệu (Distribution)

Histogram:
import matplotlib.pyplot as plt
df["revenue"].plot(kind="hist", bins=10)
plt.show()
Giúp xem:
- Dữ liệu có chuẩn không?
- Có bị lệch phải / lệch trái không?
- Có nhiều outliers không?
8. Boxplot – Phát hiện outliers
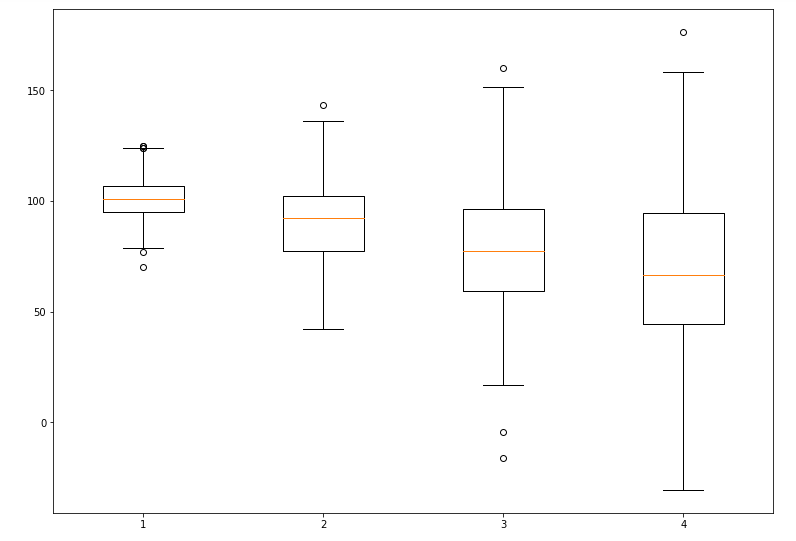

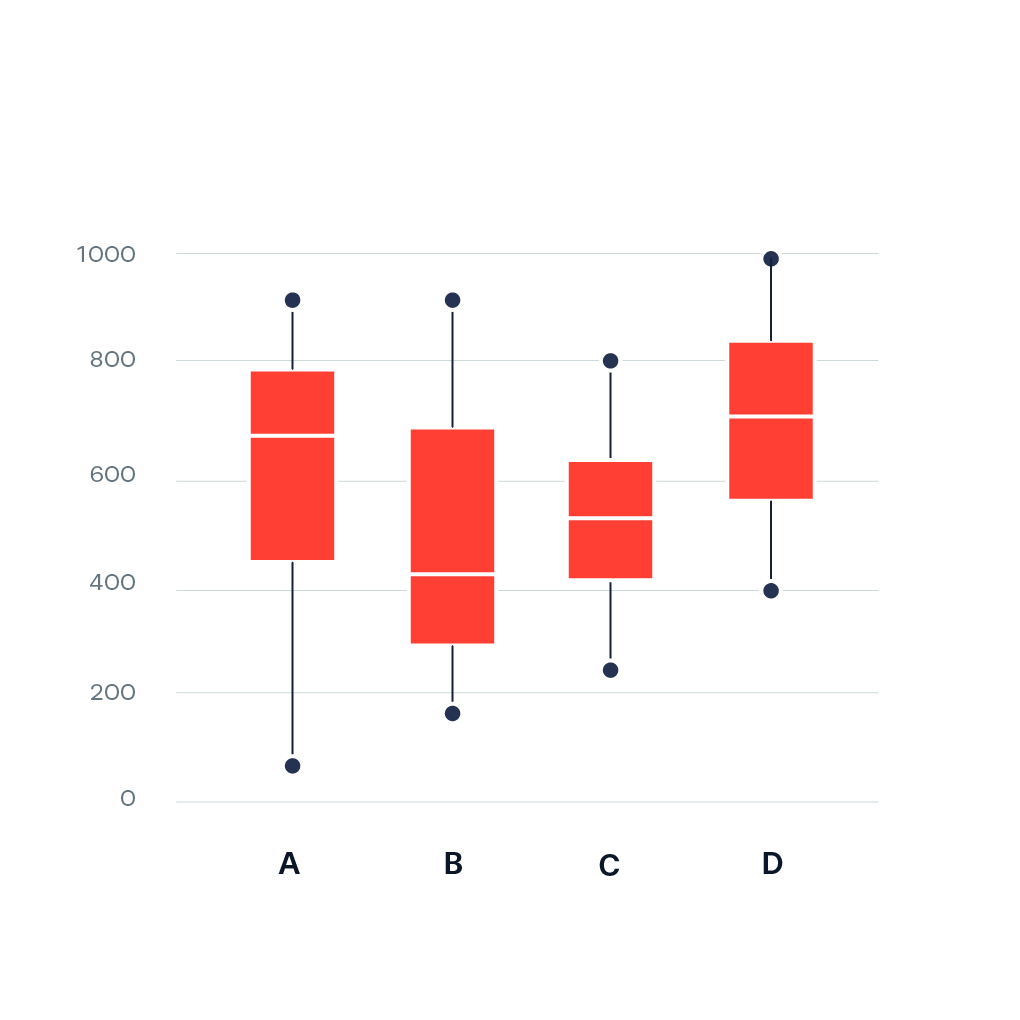
df.boxplot(column="revenue")
plt.show()
Ý nghĩa:
- Đường giữa = median
- Hộp = 50% dữ liệu
- Điểm ngoài = outliers
9. Phân tích tương quan (Correlation)
Tương quan giữa revenue và cost?
df.corr()
Vẽ heatmap:
import seaborn as sns
sns.heatmap(df.corr(), annot=True)
Ý nghĩa:
- Gần 1 → tương quan mạnh cùng chiều
- Gần -1 → tương quan mạnh ngược chiều
- Gần 0 → không tương quan
10. Phân tích theo thời gian (Time Series)
Nếu có cột date:
df["date"] = pd.to_datetime(df["date"])
df.set_index("date")["revenue"].plot()
Phân tích:
- Xu hướng (trend)
- Mùa vụ (seasonality)
- Biến động theo ngày/tuần/tháng
11. Pivot Table – siêu mạnh trong phân tích
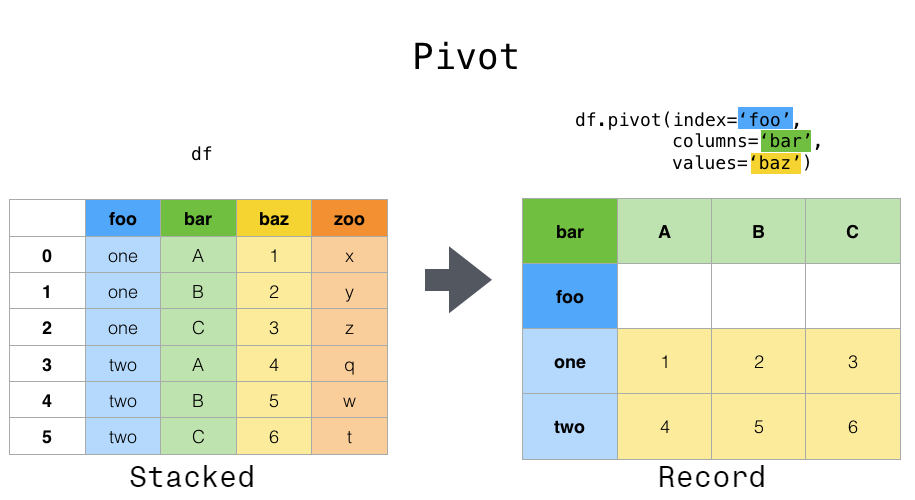
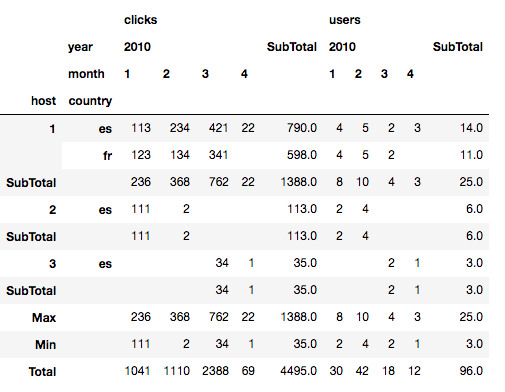

pd.pivot_table(
df,
values="revenue",
index="category",
aggfunc=["mean","sum","count"]
)
Pivot table giúp:
- Gộp dữ liệu theo nhóm
- Tính KPI
- So sánh nhóm với nhau
12. Phân tích tổng hợp (Summary Report)
Ví dụ báo cáo nhanh:
report = {
"total_revenue": df["revenue"].sum(),
"avg_revenue": df["revenue"].mean(),
"std_revenue": df["revenue"].std(),
"max_revenue": df["revenue"].max(),
"min_revenue": df["revenue"].min(),
"top_category": df.groupby("category")["revenue"].sum().idxmax()
}
print(report)
13. Kết luận
Sau bài 4 bạn đã nắm:
- Thống kê mô tả
- Trung bình – trung vị – mode
- Độ lệch chuẩn – phương sai
- Phân nhóm (groupby)
- Trực quan hóa phân phối
- Phát hiện outliers
- Phân tích tương quan
- Pivot Table
- Báo cáo tổng hợp
Đây là nền tảng của Data Analytics và Machine Learning.
Không có phân tích thống kê mô tả → Không hiểu dữ liệu → Không thể mô hình hóa.