Bài viết gần đây
| Ứng dụng Machine Learning dự đoán xu hướng Crypto: Hướng dẫn xây dựng mô hình Học Máy phân tích dữ liệu Binance API
Được viết bởi thanhdt vào ngày 29/05/2026 lúc 15:34 | 45 lượt xem

Trong giao dịch tài chính nói chung và tiền mã hóa (Cryptocurrency) nói riêng, các chỉ báo kỹ thuật truyền thống như RSI, MACD hay Bollinger Bands thường tạo ra nhiều tín hiệu giả (False Signals) do chúng chỉ là các phép toán số học tuyến tính đơn giản. Để nâng cấp hệ thống giao dịch lên một tầm cao mới, giới quantitative trader hiện nay đều ứng dụng Machine Learning (Học máy) để nhận diện các mô hình phi tuyến tính phức tạp của thị trường.
Bài viết này sẽ hướng dẫn bạn chi tiết quy trình xây dựng một mô hình Machine Learning Crypto Bot bằng Python sử dụng thuật toán Random Forest nhằm dự đoán xu hướng giá của Bitcoin dựa trên dữ liệu lấy từ API Binance.
🎨 Sơ đồ vận hành thực thi của Machine Learning Crypto Bot
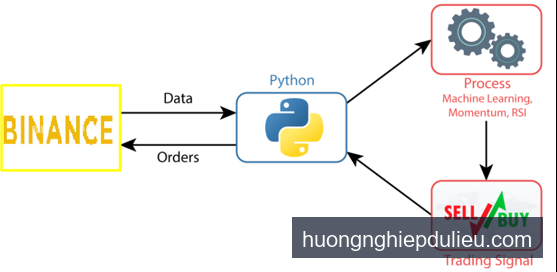
1. Ý tưởng thiết kế mô hình Machine Learning dự đoán giá Crypto
Nhìn vào sơ đồ quy trình phía trên, mô hình Học Máy của chúng ta sẽ đóng vai trò cốt lõi trong khối Process:
- Dữ liệu đầu vào (Input Features): Lấy dữ liệu nến lịch sử từ Binance API, sau đó tính toán các đặc trưng (features) động lượng như tỷ lệ thay đổi giá, RSI, độ biến động của các cây nến trước.
- Nhãn mục tiêu (Target Label): Xác định xu hướng của cây nến tiếp theo. Nếu giá đóng cửa nến tiếp theo cao hơn nến hiện tại, nhãn sẽ là 1 (TĂNG – BUY), ngược lại sẽ là 0 (GIẢM – SELL).
- Huấn luyện (Training): Sử dụng thuật toán phân loại Random Forest Classifier để học mối quan hệ giữa các đặc trưng đầu vào và nhãn mục tiêu.
- Tín hiệu (Trading Signal): Khi có dữ liệu nến mới từ Websockets, mô hình dự đoán nhãn 1 hay 0 để phát tín hiệu giao dịch tự động.
2. Các thư viện Python cần thiết
Để thực hiện dự án này, bạn cần cài đặt các thư viện phân tích dữ liệu và học máy phổ biến sau:
pip install python-binance pandas numpy scikit-learn
3. Lập trình xây dựng mô hình Học máy từ A – Z bằng Python
Dưới đây là toàn bộ mã nguồn Python thực chiến giúp bạn thu thập dữ liệu từ Binance, tiền xử lý, huấn luyện mô hình Random Forest và đưa ra dự đoán xu hướng giá:
import os
import numpy as np
import pandas as pd
from binance.client import Client
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
# Bước 1: Kết nối API Binance và tải dữ liệu nến lịch sử
def download_binance_data(symbol="BTCUSDT", interval=Client.KLINE_INTERVAL_15MINUTE, limit="15 days ago UTC"):
print("🔄 Đang tải dữ liệu từ Binance API...")
api_key = os.getenv("BINANCE_API_KEY")
api_secret = os.getenv("BINANCE_API_SECRET")
client = Client(api_key, api_secret)
klines = client.get_historical_klines(symbol, interval, limit)
df = pd.DataFrame(klines, columns=[
'Open Time', 'Open', 'High', 'Low', 'Close', 'Volume',
'Close Time', 'Quote Asset Volume', 'Number of Trades',
'Taker Buy Base Asset Volume', 'Taker Buy Quote Asset Volume', 'Ignore'
])
# Định dạng lại dữ liệu
df['Close'] = df['Close'].astype(float)
df['Volume'] = df['Volume'].astype(float)
df['High'] = df['High'].astype(float)
df['Low'] = df['Low'].astype(float)
return df[['Close', 'Volume', 'High', 'Low']]
# Bước 2: Kỹ nghệ đặc trưng (Feature Engineering)
def prepare_features(df):
print("🛠 Đang xử lý Kỹ nghệ đặc trưng (Feature Engineering)...")
# 1. Tính toán lợi suất phần trăm (Returns)
df['Return'] = df['Close'].pct_change()
# 2. Tính chỉ báo động lượng cơ bản (Momentum)
df['Momentum_5'] = df['Close'] - df['Close'].shift(5)
df['Momentum_10'] = df['Close'] - df['Close'].shift(10)
# 3. Tính biến động giá (Volatility)
df['Volatility_5'] = df['Return'].rolling(window=5).std()
df['Volatility_10'] = df['Return'].rolling(window=10).std()
# 4. Xác định nhãn mục tiêu (Target): 1 nếu nến sau tăng giá, 0 nếu nến sau giảm giá
df['Target'] = np.where(df['Close'].shift(-1) > df['Close'], 1, 0)
# Loại bỏ các dòng chứa giá trị rỗng (NaN) do tính toán shift/rolling
df.dropna(inplace=True)
return df
# Bước 3: Huấn luyện mô hình Random Forest
def train_machine_learning_model(df):
# Khai báo các biến đặc trưng đầu vào (X) và nhãn dự đoán (y)
feature_cols = ['Close', 'Volume', 'Return', 'Momentum_5', 'Momentum_10', 'Volatility_5', 'Volatility_10']
X = df[feature_cols]
y = df['Target']
# Chia tập dữ liệu thành 80% Huấn luyện (Train) và 20% Kiểm thử (Test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, shuffle=False)
print(f"🌲 Đang huấn luyện mô hình Random Forest (Tổng số mẫu: {len(X_train)})...")
# Khởi tạo mô hình Random Forest với 100 cây quyết định
model = RandomForestClassifier(n_estimators=100, max_depth=8, random_state=42)
model.fit(X_train, y_train)
# Đánh giá hiệu suất mô hình trên tập kiểm thử
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("n================ ĐÁNH GIÁ MÔ HÌNH ================")
print(f"🎯 Độ chính xác dự đoán (Accuracy): {accuracy * 100:.2f}%")
print("nBáo cáo chi tiết phân loại:")
print(classification_report(y_test, y_pred))
return model
# Chạy quy trình thực thi thử nghiệm
if __name__ == "__main__":
raw_data = download_binance_data()
processed_data = prepare_features(raw_data)
ml_model = train_machine_learning_model(processed_data)
4. Giải thích thuật toán Random Forest trong giao dịch Crypto
Mô hình sử dụng thuật toán Random Forest (Rừng ngẫu nhiên) – một trong những thuật toán học máy mạnh mẽ và phổ biến nhất cho bài toán phân loại. Nó hoạt động bằng cách xây dựng hàng trăm cây quyết định (Decision Trees) song song và lấy số phiếu bầu số đông để đưa ra dự đoán cuối cùng.
- Ưu điểm vượt trội: Giảm thiểu hiện tượng quá khớp (Overfitting), xử lý tốt các dữ liệu phi tuyến tính phức tạp của thị trường Crypto, và cung cấp mức độ quan trọng của từng đặc trưng (Feature Importance) để nhà giao dịch hiểu rõ yếu tố nào đang ảnh hưởng lớn nhất đến xu hướng giá.
- Chiến lược tối ưu nâng cao: Trong thực tế, các quantitative trader chuyên nghiệp sẽ kết hợp thêm các đặc trưng nâng cao như dữ liệu Orderbook (Sổ lệnh), chỉ số Funding Rate, và dữ liệu On-chain để nâng cao độ chính xác dự đoán lên trên 60-65% – tỷ lệ đủ để tạo ra lợi nhuận kép cực khủng trong dài hạn.
🎓 Khóa học "Lập trình Bot Auto Trading & Machine Learning thực chiến" tại Hướng Nghiệp Dữ Liệu
Bạn muốn làm chủ hoàn toàn các kỹ thuật Học máy nâng cao (như LSTM, Neural Networks, Random Forest) để tối ưu hóa hiệu suất giao dịch tự động của riêng mình? Bạn muốn học cách tích hợp mô hình Machine Learning trực tiếp vào luồng Websocket của Binance để đặt lệnh tức thời?
Hãy đăng ký ngay khóa học "Xây dựng Bot Auto Trading thực chiến" của Hướng Nghiệp Dữ Liệu:
- Chuyên sâu thực tế: Đào tạo kỹ năng làm sạch dữ liệu, xử lý nhiễu dữ liệu thị trường và thiết kế đặc trưng độc quyền.
- Trải nghiệm thực tế: Cầm tay chỉ việc viết code kết nối API, cấu hình VPS đám mây để chạy mô hình tự động 24/7.
- Đồng hành trọn đời: Hỗ trợ giải đáp thắc mắc và sửa lỗi code trọn đời bởi đội ngũ chuyên gia công nghệ hàng đầu.
👉 Đăng ký nhận lộ trình học tập chi tiết và ưu đãi học phí qua Zalo: